In today’s fast-paced and highly competitive business landscape, data has become a crucial element for success. Companies rely on vast amounts of data to make strategic decisions, drive growth, and improve customer experience. However, with the ever-growing volume and complexity of data, it can be challenging to manage, analyze, and utilize this information effectively. This is where data pipelines come in – as a solution to streamline the process of collecting, transforming, and delivering data to its intended destination.
Data pipeline refers to a series of automated actions that extract data from various sources, transform it into a usable format, and load it into a target destination for further analysis or use. It acts as a bridge between different systems, applications, and databases, ensuring that data flows seamlessly and accurately across the entire process. In this article, we will delve deeper into the world of data pipelines, its importance, and how it can benefit businesses of all sizes.
Understanding Data Pipeline
What is a Data Pipeline?
A data pipeline is a series of automated steps that move data from its original source to a destination where it can be analyzed, processed, or used for a specific purpose. It serves as a conduit through which data flows, ensuring that information is collected, transformed, and delivered accurately and efficiently.
The process starts with the extraction of data from various sources, such as databases, files, or applications. This data is then transformed into a usable format, usually through cleaning, filtering, or aggregating, before loading it into the target destination. The data pipeline can also include actions such as validation, enrichment, and data quality checks to ensure that the data is accurate and consistent.
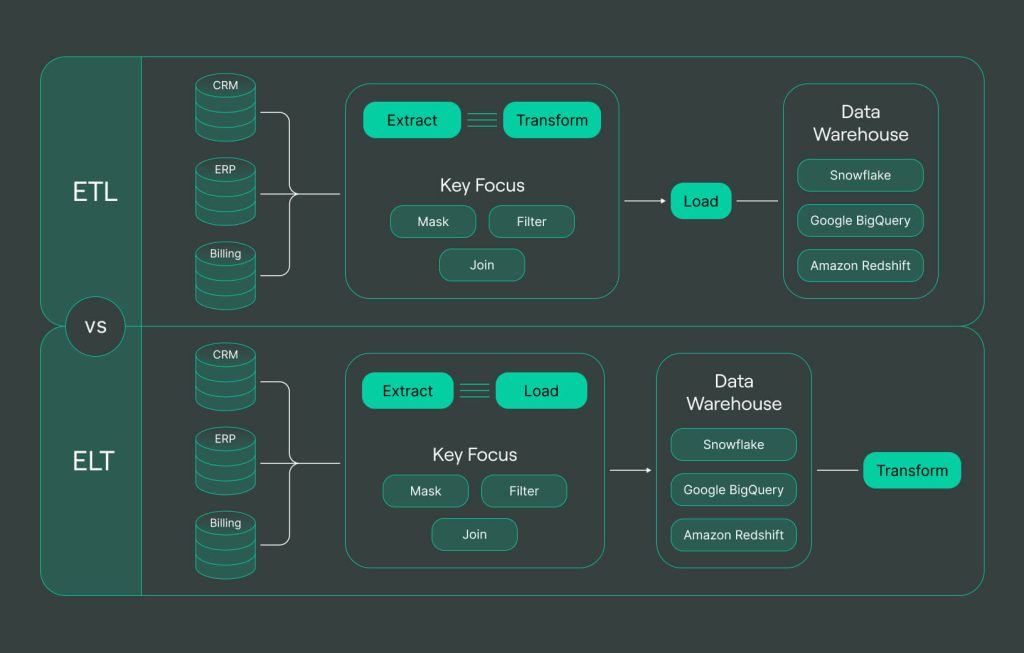
A data pipeline consists of automated stages that transfer data from its origin to a destination for analysis, processing, or specific utilization
The Components of a Data Pipeline
A data pipeline consists of several components, each playing a crucial role in the overall process. These components are:
- Data Source: This refers to the origin of the data, whether it’s an application, database, or file.
- Data Ingestion: This is the process of extracting data from its source and moving it to the next stage of the pipeline.
- Data Transformation: This involves manipulating and shaping the data into a usable format for analysis or use.
- Data Loading: This is the final step where the transformed data is loaded into a target destination, such as a data warehouse or a cloud storage system.
- Data Processing: This can include any additional processing or analysis performed on the data after it has been loaded into the destination.
- Data Visualization: This involves presenting the data in a visual format, making it easier to interpret and analyze.
Types of Data Pipelines
There are two main types of data pipelines – batch and streaming. A batch pipeline processes data in batches, meaning it collects and transforms data at regular intervals, while a streaming pipeline processes data in real-time as it becomes available. Both types have their advantages and are suitable for different use cases.
Batch data pipelines are ideal for scenarios where the data doesn’t need to be processed immediately, such as generating weekly or monthly reports. It is a cost-effective option as it can handle large volumes of data at once, reducing the processing time and resources needed. On the other hand, streaming pipelines are better suited for use cases that require real-time analytics, such as fraud detection or monitoring website traffic. It allows for quick decision-making based on up-to-date data and enables businesses to respond promptly to any changes or anomalies in their data.
Benefits of Implementing a Data Pipeline
Improved Data Quality and Consistency
Data quality and consistency are essential for accurate and meaningful analysis. A data pipeline ensures that data is extracted, transformed, and loaded consistently, eliminating errors and inconsistencies that may arise from manual processes. With automated data cleansing and validation, businesses can trust that the data being used for decision-making is reliable and accurate.

A data pipeline guarantees consistent extraction, transformation, and loading of data, minimizing errors and inconsistencies typically associated with manual procedures
Real-time Data Processing
One of the significant advantages of using a data pipeline is its ability to process data in real-time. This means that businesses can receive insights and make decisions based on up-to-date information, rather than relying on outdated reports. Real-time data processing becomes crucial in fast-paced industries, such as finance and e-commerce, where timely actions can make all the difference.
Increased Efficiency and Productivity
Manual data collection, transformation, and loading processes can be time-consuming and prone to errors. By automating these tasks through a data pipeline, businesses can save valuable time and resources, allowing employees to focus on more critical tasks. This leads to increased efficiency, improved productivity, and ultimately, better business outcomes.
Cost Savings
Implementing a data pipeline can also lead to cost savings for businesses. As mentioned earlier, automation reduces the time and resources required for data processing, saving companies money in the long run. Additionally, with real-time data processing, businesses can quickly detect and fix any issues, preventing potential revenue loss.
Building an Effective Data Pipeline
Building an efficient data pipeline requires proper planning, clear objectives, and a thorough understanding of the data sources and destinations. Below are some essential steps to consider when building a data pipeline for your business.

Constructing an effective data pipeline necessitates careful planning, defined goals, and a deep understanding of both data origins and destinations
Identifying Data Sources
The first step in building a data pipeline is identifying the data sources you want to include. This could be databases, applications, or files that contain relevant data for your business. It’s crucial to have a clear understanding of the data that your company needs to collect and analyze to determine which sources are necessary for your data pipeline.
Defining Data Flow
Once you have identified your data sources, the next step is defining the flow of data. This involves mapping out the entire process, from data ingestion to loading. It’s essential to understand how data moves through each stage and what actions are taken at each step. This will help identify any potential bottlenecks or areas that require improvement.
Data Transformation and Integration
Data transformation is a crucial component of a data pipeline. It involves cleaning, filtering, and aggregating data to make it usable for analysis or use. Depending on the complexity of your data, you may need to use different tools or techniques for transformation, such as coding, scripting, or using specialized software.
Integrating data from multiple sources is also an essential aspect of building a data pipeline. This ensures that data from different systems or applications can be combined and analyzed to provide meaningful insights. Data integration can be challenging, especially if the data is stored in different formats or systems. However, there are various tools available that can help streamline this process.
Challenges and Solutions in Data Pipeline Implementation
While data pipelines offer several benefits to businesses, there are also potential challenges that may arise during implementation. Here are some common challenges and possible solutions to overcome them.
Data Security and Privacy Concerns
With the increasing amount of data being collected and processed, data security has become a critical concern for businesses. Data breaches can have severe consequences, including financial loss and damage to a company’s reputation. It’s essential to implement proper security measures at each stage of the data pipeline to protect sensitive information. This could include encryption, access controls, and regular security audits.
Data privacy is also a significant concern, especially with regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) in place. Businesses must ensure that they are compliant with these regulations when collecting, storing, and processing personal data. This may involve implementing data masking or anonymization techniques to protect personal information.
Data Governance and Compliance
In addition to data security and privacy concerns, data governance and compliance are also crucial aspects of data pipeline implementation. Data governance refers to the policies, processes, and controls put in place to manage and protect data. It ensures that the data being used is accurate, consistent, and conforms to internal and external regulations.
Businesses must also comply with various regulations and standards when handling data, depending on their industry. For example, healthcare organizations must adhere to the Health Insurance Portability and Accountability Act (HIPAA), while financial institutions must comply with the Sarbanes-Oxley Act (SOX). To ensure compliance, businesses must have proper data governance practices in place and regularly audit their data pipelines.
Scalability and Flexibility
As businesses grow, so does the volume and complexity of their data. This makes it essential to have a scalable and flexible data pipeline that can handle changing demands. A common mistake businesses make is building a data pipeline that only meets their current needs without considering future growth. This can lead to bottlenecks and delays when more data needs to be processed.
To avoid this, businesses must plan for scalability and flexibility when building their data pipeline. This could involve using cloud-based solutions that can scale as the volume of data increases or choosing a data pipeline tool with built-in scalability features.
Tools and Technologies for Data Pipeline Management
Managing a data pipeline can be a complex and time-consuming process, especially for businesses with vast amounts of data. Fortunately, there are various tools and technologies available to help streamline this process and make it more manageable. When choosing a data pipeline tool, here are some features to consider:
- Ease of Use: The tool should be user-friendly, with a simple interface that allows users to set up, monitor, and manage the data pipeline easily.
- Data Integration Capabilities: The tool should have the ability to integrate data from various sources, including databases, files, and applications.
- Data Transformation Features: Look for a tool that offers a wide range of data transformation capabilities, such as cleaning, filtering, and aggregating data.
- Real-time Processing: If your business requires real-time analytics, choose a tool that can handle streaming data and process it in real-time.
- Scalability and Flexibility: As mentioned earlier, scalability and flexibility are essential for a data pipeline tool. Ensure that the tool can handle changing demands and can scale accordingly.
- Data Security and Compliance: The tool should have robust security measures in place to protect sensitive data, and must also comply with relevant regulations and standards.
- Cost: Consider the cost of the tool and whether it fits within your budget. Some tools may offer free trials, while others require a subscription or one-time payment.
Some popular data pipeline tools include Apache Airflow, AWS Glue, and Informatica. It’s essential to evaluate each tool based on your specific needs and choose one that best suits your business.
Conclusion
In today’s data-driven world, having an efficient data pipeline is crucial for businesses of all sizes. It streamlines the process of collecting, transforming, and delivering data, ensuring that businesses have access to accurate and timely information. With the right data pipeline in place, companies can improve their decision-making, increase productivity, and gain a competitive edge in their industry.
In the future, we can expect to see more advancements in data pipeline management, such as the integration of artificial intelligence and machine learning to automate certain tasks further. As data volumes continue to grow, it will become increasingly important for businesses to invest in an effective data pipeline to stay ahead of the competition.

